
During my undergraduate studies, I had the privilege of working with some of the coolest hackers in the world: folks in my research lab wouldn’t hesitate to strap their latest prototype (loose wires and all) to their bodies to test out new modes of interaction between humans and their computers. And all in the name of science! This culture of fearless experimentation rubbed off on me.
As I dove deeper into the literature of intelligence augmentation, one MIT Media Lab project always came to the fore: the remembrance agent (RA), a continuously-running automated information retrieval system. The implications of this project were quite profound. Rhodes et al. demonstrated that the RA could effectively augment a person’s contextual knowledge to include all relevant documents ever recorded by that person on a computer.
In the past few years, I’ve also had the opportunity to talk with folks who have been using such systems for decades. These conversations gave me great insight into how such memory augmentation systems can improve the way our brains structure information and how we take notes to make the best use of a hybrid human-computer information system.
One such individual, who has been wearing a head-worn display continuously for almost 25 years, shared with me the profound impact that wearable “always-on” computer systems had on his memory functions. He doesn’t have executive memory; he needs an artificially-imposed structure for memory to remember what most of us can recall with ease. After a few years of taking and recalling notes through an HWD, his mind passively1 learned how to develop memory maps allowing him to learn naturally in the physical world even when not using a HWD.
Following the spirit instilled in me by research colleagues. I decided to run a long-term experiment on myself: I wanted to understand first-hand how living and working with a memory augmentation tool for a year could improve the way I relate to the knowledge in my brain and in my computer.
I’ve been living and working with a memory augmentation tool for almost a year.
Background
From [Rhodes 1997], “the Remembrance Agent (RA) is a program that augments human memory by displaying a list of documents that might be relevant to the user’s current context. Unlike most information retrieval systems, the RA runs continuously without user intervention. Its unobtrusive interface allows a user to pursue or ignore the RA’s suggestions as desired.”
[Rhodes 1996] originally conceived of the remembrance agent as an extension for the Emacs text editor. [Rhodes 1997] integrated the remembrance agent for use with wearable computers like head-worn displays.
However, I am not an active user of Emacs (I prefer graphical text editors). Further, there’s no remembrance agent application for the one head-worn display I routinely use (Google Glass). I use Google Docs for all my non-academic note-taking. (I still prefer pen-to-paper note-taking for coursework.) I use a single Gmail account for all email communication. (My email threads have become a substantial store of useful information as offline/async communication has become more important in my day-to-day life.)
For a remembrance agent to be useful to me, documents need to be indexed and synced from my Google Drive and Gmail. Plus, I want to use a remembrance agent on my PC where I write most of my emails and take most of my meeting notes. This requires a reimplementation of the original C-based remembrance agent in a more modern and portable toolset.
Development
I settled on Java for this project because of its use in developing Android applications and its strong cross-platform support for graphical user interfaces (GUIs) through Java Swing and JavaFX.
I created a no-dependency, pure-Java, Gradle-based project that encapsulates the core functionality of the remembrance agent. Following [Rhodes 1997], I sketched out a simple interface for the “Remembrance Agent Engine” (i.e. the core of the project). Conceptually, there are three functions required to setup and interact with a remembrance agent
void loadDocuments()which will pull documents from all the required data sources into the system,void indexDocuments()which will perform all the preprocessing required to efficiently produce contextually-useful document suggestions, andList<ScoredDocuments> determineSuggestions(Query)which will take in a contextually-aware query and return a list of documents and their relevance scores.
These three functions map clearly to the IRemembranceAgentEngine interface resting at the core of this project. The implementation of this interface closely follows that of [Rhodes 1997].
Data models
An AbstractDocument is the base class for every type of document that can be ingested by the RemembranceAgentEngine. It holds the text of a document as well as contextual information about the document. The various contextual factors of each document are encapsulated in a Context. These factors include:
- the location of the user,
- the name of the user (i.e. the
person), - a short description of the subject of the query, and
- the date this query.
There are numerous concrete subclasses of AbstractDocument which lend to numerous integrations like those for Gmail and Google Drive. A collection of AbstractDocuments is stored in an implementation of IDocumentDatabase.
A Query tells the RemembranceAgentEngine’s determineSuggestions method about the context of a query and provides a query string used to search for relevant documents based on their contents. A query has an associated Context which is compared with each document’s own Context to determine if the document is relevant to the query.
Determining suggestions
The implementation of determineSuggestions is quite involved. At a high-level, each document’s text is windowed into smaller strings before comparison with a query. (Currently, each window is simply a single line of the document’s content as delimited by newlines.) Windowing allows for TFiDF to match a query string against smaller selections of text within large documents.
The content similarity score for an entire document is calculated by summing up the TFiDF similarity score between each window of the document against the query string. This cumulative score is weighted against the similarity scores for the contextual factors (location, date, etc.) to form the similarity index for each document relative to the given query. The scored documents are sorted descending and the top Query::numSuggestions are returned from determineSuggestions.
Deployment
I sought to use the remembrance agent on my desktop and on Google Glass. As such I enclosed the core remembrance agent functionality in a no-dependency Gradle remembrance-agent project that can easily be imported into other Java runtime projects.
Glass Notes integration
During my first quarter of graduate school I took lecture notes and meeting notes on Google Glass. I integrated the remembrance-agent package into this Glass Notes application to pull up contextually-relevant notes for my meetings and lectures. (The diff for this integration is useful for those interested in their own such integrations for other Java applications.)
Remembrance Agent Desktop GUI
My primary interface to the remembrance agent has been through a desktop GUI.
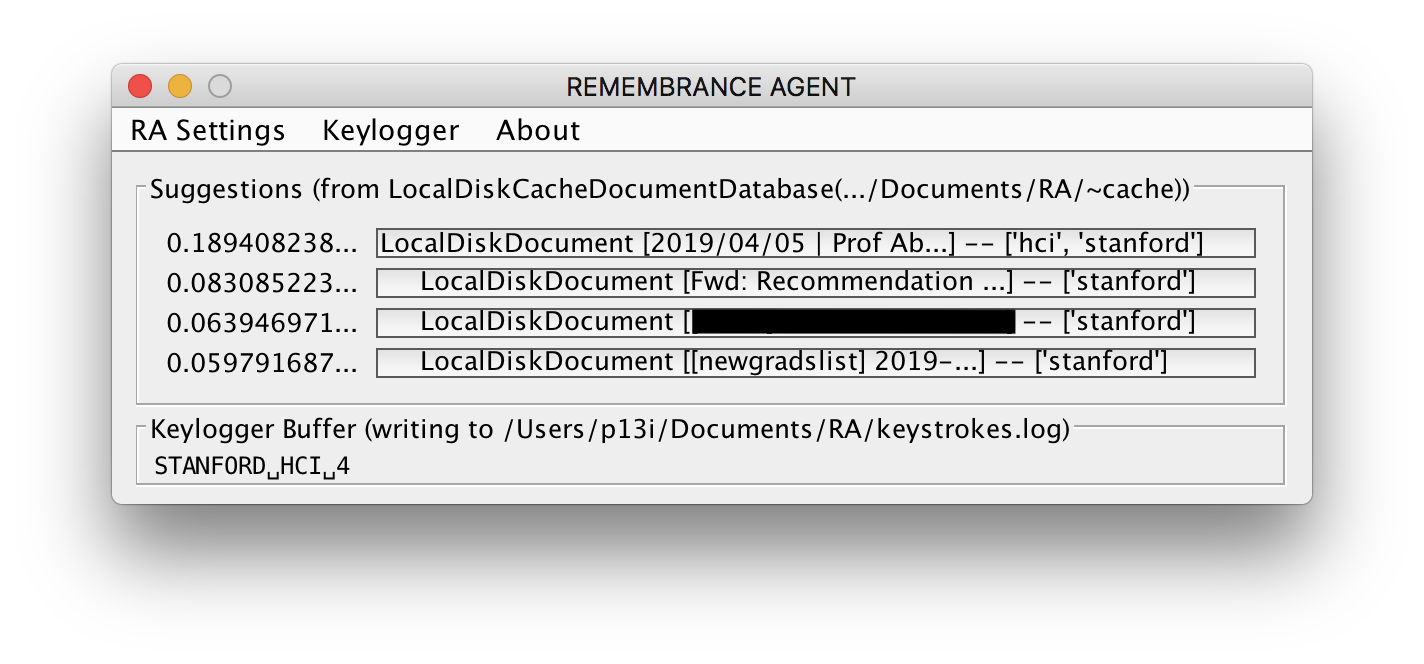
As I go about my normal typing tasks, my keystrokes are recorded into the “Keylogger Buffer” at the bottom of the window. Every 5 seconds, the contents of the keyboard buffer is sent as part of a query to the remembrance agent engine. This ‘engine’ returns the top 4 documents ranking by their relevance score (displayed on the left of each document).
Findings
After using remembrance agents for a year, I’ve noticed some subtle changes in the way I relate to my digital footprint.
Forgotten documents
There were numerous times when I was composing an email or taking notes in a meeting where the remembrance agent would pull up emails or documents from years ago that I had completely forgotten about.
When writing an email to a colleague about “wearable computers,” my remembrance agent pulled up my meeting notes on a conversation I had with a brilliant wearable computing researcher from years ago. With these notes at hand, I was able to augment the content of my email to reflect knowledge I had gained from the past.
I also found the remembrance agent useful when composing reports, articles, or papers where various tidbits of wisdom improve the content at hand.
Extended memory map
The remembrance agent’s constant search for relevant documents reinforces connections between my current context and past documents. I’ve noticed that I have a strong and faster mental recall of older documents.
(More such findings will be added here with time.)
-
By “passive” I simply mean that he was not putting in a conscious effort. ↩
This site is open source. Improve this page »